Code Style Changes
It appears that working with competent developers who actually get things done has had an observable effect on my coding style over the last year.
Learning from my own mistakes, coworkers’ feedback and from reading other people’s code
Neatness and code aesthetics count for a lot in my book. So naturally, if I see someone whose style is a bit different but is neat and seems sensible, I’ll shamelessly steal mimic their way for a while to see if it’s a good fit—if it is, I keep it, if not, I discard it. If someone tells me something I’m doing stinks, I may grumble a bit, but usually end up spending some time reflecting internally to see if I need to change or if that person was just being a tool.
These are a few of changes I’ve made to my coding style since 2014.
Indentation: Spaces over tabs, two spaces vs four
This took a while to get used to and I fought it pretty hard. I was used to seeing the world like this:
/**
* Mimics the behavior of PHP's print_r() function
*
* @param {string} subject The object or value to be dumped
* @param {bool} suppressPrint This is true by default; will only return the dump, not print
* @returns {string} Always returns the dumped value
*/
function print_r(subject, suppressPrint) {
function recurse(subject, padding) {
var buf = '';
// Determine the proper type for the subject
var friendlyType;
if (subject instanceof Array)
friendlyType = 'Array';
else if ('object' === typeof subject)
friendlyType = 'Object';
else
friendlyType = typeof subject;
// If a simple primitive, just dump it
if (friendlyType.match(/(string|number)/i))
return subject;
// Header
buf += friendlyType + "\n" + padding + "(\n";
// Print each element; if array or object, recurse into it
for (var i in subject) {
buf += padding + " [" + i + '] => ';
if ((typeof subject[i]).match(/(array|object)/i))
buf += recurse(subject[i], padding + "\t") + "\n";
else
buf += subject[i] + "\n";
}
// Footer
buf += padding + ")";
return buf;
}
var output = recurse(subject, '');
if (false === suppressPrint)
document.write(output);
return output;
}
And when it didn’t look that way, I’d meticulously reformat the entire source file and commit that as “Format indentations” before even jumping into the code.
But the thing is, I think the four space indentations were a crutch I was relying on to cover up some bad habits, e.g., deferring refactor of gigantic functions, omitting curly braces, etc. In reality, those gigantic functions should have been refactored and being “easier to read” served as an excuse not to refactor. And I’ve since gotten into the habit of putting curly braces everywhere.

As for the spaces vs. tabs thing…
Line continuations are what finally did me in. I kept getting into fights with the IDE, which wanted to replace four spaces with a tab when I would try to align arguments like this:
someOperation('really-long-string-that-crowds-out-other-arguments',
'foo', 'bar')
// ^^^^ --- IDE: <TAB>, you're welcome!
// ^^^^ --- IDE: <TAB>, you're welcome!
Then, when I pushed the code to GitHub (who, one day, up and switched to showing tabs at 8 spaces by default all the time), it’d look like this:
someOperation('really-long-string-that-crowds-out-other-arguments',
'foo', 'bar')
// ^^^^^^^^ --- Github: let's expand tabs fully. gfy tabbers, lol!
// ^^^^^^^^ --- Github: let's expand tabs fully. gfy tabbers, lol!
So yes, the classic spacer argument that “it looks the same in all environments” did me in. I resent the spacers for overplaying their hand but to be honest, spaces and tabs don’t even register to me anymore. And at least now, I can be a little more PEP8 compliant. :)
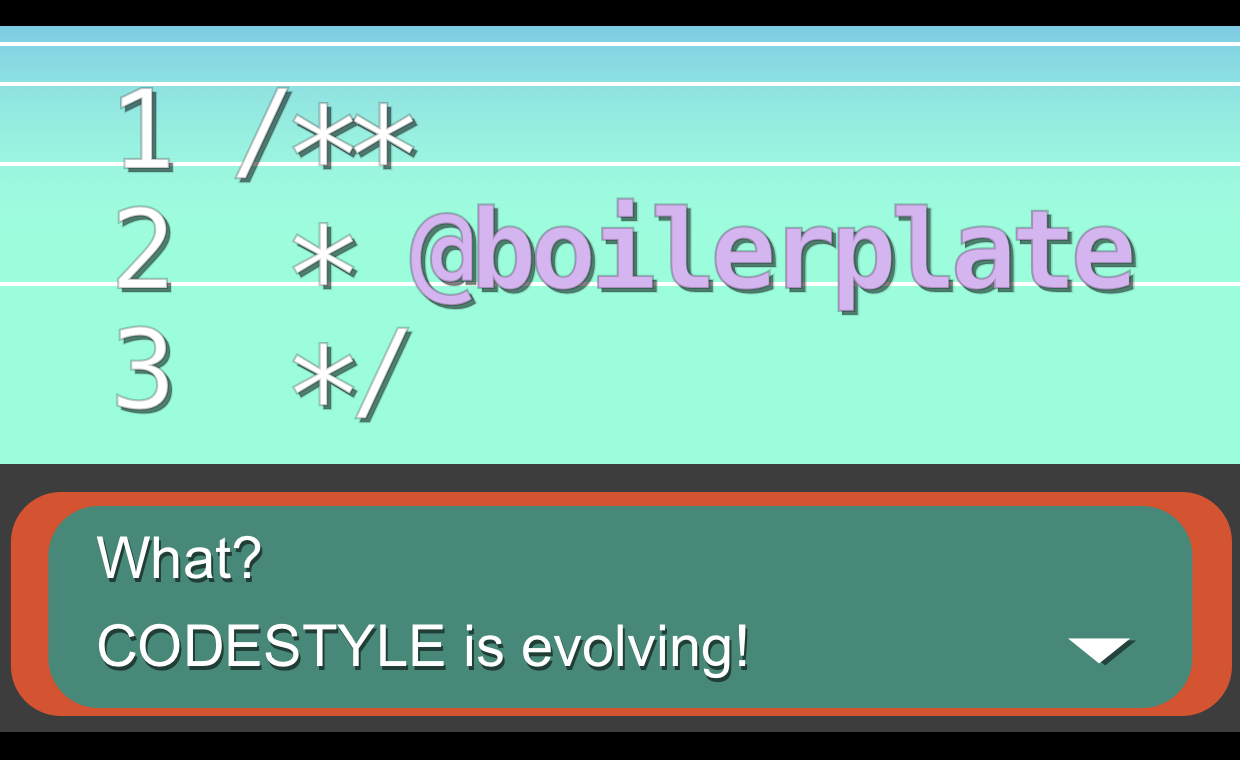
Noise Reduction/DRY: Omitting boilerplate docblocks
This is easily the biggest change of the year and the one that has the most impact as it applies to more than just JavaScript. I’ve stopped dropping redundant boilerplate docblocks into my code, ala:
class FormProcessor {
/**
* Normalizes the input value.
*
* @param {string} unsafe
* @return {string}
*/
_normalizeInputValue(unsafe) { /* ... */ },
/**
* Returns a string representation of this instance.
*
* @return {string}
*/
toString() { /* ... */ }
}
(contrived example)
Earlier this year, I had several spirited debates with one of my more combative fellow devs about my liberal use of comments and my adding of docblocks to every function. He’d say things like “code should be self documenting”, which, of course, was a declaration of World War III. My reaction was to immediately create a mental straw man of his argument. Onto that straw man, I pinned every negative encounter I’ve ever had with ridiculously complex, ambiguous and uncommented code, as if he had said that having massive complex functions without docs and comments is ok. I then went DEFCON 1 on that straw man.
I tend to dwell on these kinds of exchanges, and after a while I realized that I completely agreed with the crux of what he said, that code should be self documenting. Up until that point, I’d often ask myself if it really made sense to add a docblock to a function whose name already explains exactly what it does before just putting the damn thing there because there are docblocks everywhere else.
Fast forward to about two weeks ago when I read Erik Dietrich’s blog post about The Death of the Obligatory Comment which formalized (and made fit for non-inflammatory dialogue between adults) what my teammate was saying:
How many of those comments that I wrote are still floating around in some code base somewhere, not deleted? And of that percentage, how many are accurate? I’m guessing the percentage is tiny — the comments are dust in the wind. And before they blew away, what are the odds that anyone cared enough to read them?
…
If I want to make my code usable and understandable, I have to do it with tight abstractions, self-documenting code and making bad decisions impossible. Is that a lofty goal? Sure. But I think it’s a good one. I’ve gone from viewing comments as obligatory to viewing them as indicative of small design failures, and I’m content with that.
Erik doesn’t go as far as to call comments a code smell, but he does a better job explaining this than I can, so I won’t belabor the point.
Here’s the revised FormProcessor
class FormProcessor {
processComplexOperation(userInput) {
const foo = this._normalizeInputValue(userInput);
const bar = this._convertToBar(foo);
const {boo, baz} = this._calculate(foo, bar);
const wat = this._synchronize(boo, baz);
return this._finalize(wat);
},
toString() { /* ... */ },
_convertToBar(foo) { /* ... */ },
_finalize(wat) { /* ... */ },
_normalizeInputValue(unsafe) { /* ... */ },
_synchronize(thing1, thing2) {
/*
* 2015-09-05
* There exists a strange edge case that prevents the
* form processor from properly synchronizing the
* gizmotron with the transmogrifier when the input
* signals from both are high.
*
* This behavior is expected to be resolved with the next
* release of SuperblyAwesomeFramework v2.0 next year.
*/
/* ... */
}
}
As you can see, the trick here is relying on descriptive method names and method composition—refactoring a big gigantic function that needs comments to explain everything it does into several smaller ones that do just one thing each.
It is worth noting that I didn’t throw the baby out with the bathwater here—the ambiguous edge case around _synchronize() gets documented because that’s something that would be very difficult to express via method naming without torturing the source code to do so.
Declaring mutable references with let and immutable references with const
ES6 Conventions:
- use
constby default.- use
letif you have to rebind a variable.- use
varto signal untouched legacy code.Reginald Braithwaite (@raganwald)
This definitely resounded with me because I’m a big fan of Swift’s var and let semantics. I first encountered this idea when I read through the Airbnb JavaScript Style Guide which calls for using const for everything and let for any variable you need to rebind. Their reasoning is that it closes one vector for bugs since you can easily see what references are mutable just by looking at the code.
const spaghetti = 'delicious';
let temperature = 'great';
if (degrees > 95) {
temperature = 'terrible';
}
Raised an eyebrow with one of my team members (which is what prompted me to seek out the @raganwald tweet), but I’m sticking with it. I like the semantics of it (even if Babel is just turning it back into a var on the way out anyway).
Avoiding gratuitous empty lines
One thing that the composed method pattern and culling of comments allows is for me to shorten the height of my functions. I was in the habit of writing code like this:
/**
* Populates the page with the search results
*
* @param {Array} results
* @param {String} context
* @param {String} query
*/
asic.PageController.prototype.displaySearchResults = function(results, context, query) {
var resultBuffer = '',
tagBuffer, currentResult, currentTag, i, j;
if (results instanceof Array) {
if (results.length) {
for (i in results) {
currentResult = results[i];
// Get the tags
tagBuffer = [];
for (j in currentResult.tags) {
currentTag = currentResult.tags[j];
// If this is the tag that matched the search, highlight it
if ('tag' === context && currentTag.match(query)) {
tagBuffer.push('<a href="?tag=' + currentTag + '" class="direct-hit">' + currentTag + '</a>');
} else {
tagBuffer.push('<a href="?tag=' + currentTag + '">' + currentTag + '</a>');
}
}
// Get the result
resultBuffer += this._resultTemplate
.replace('____NUM____', parseInt(i) + 1)
.replace('____URL____', currentResult.filename)
.replace('____TITLE____', currentResult.subject)
.replace('____PUBLISHEDON____', currentResult.publishedon)
.replace('____ABSTRACT____', currentResult.abstract)
.replace('____TAGS____', tagBuffer.join(', '));
}
// Update the page
this._resultContainer.innerHTML = resultBuffer;
this.updateSearchHeaders(results.length, context, query);
this.setState(this.STATE_HAS_RESULTS);
} else {
this.setState(this.STATE_NO_RESULTS);
}
} else {
this._callbacks.FatalError(new Error("'results' must be an array"));
}
};
Note the gratuitous empty lines because the sheer heft of that method makes it hard to read without. What should have happened was that all those little things the public method does should have been extracted to smaller single-purpose private methods.
Ignoring the grotesque implementation (it was early 2013…) and pretending that the internal methods I will be delegating actions to actually exist, this is how I would restructure it today:
asic.PageController.prototype.displaySearchResults = function(results, context, query) {
if (Array.isArray(results)) {
if (results.length) {
this._renderIntoContainer(results);
this._updateSearchHeaders(results.length, context, query);
this._setState(this.STATE_HAS_RESULTS);
} else {
this._setState(this.STATE_NO_RESULTS);
}
} else {
this._emitError("'results' must be an array");
}
};
Writing it this way obviates the need for all of those one-liner // hey, this is what I'm doing now comments. And once the one-liners and extra operations are gone, there’s less need for empty lines. What’s left is a short understandable and beautiful block of code. :)